Semantic Textual Similarity (STS) evaluation is a standard way to measure how well an embedding model captures meaning. You present the model with pairs of sentences, compute the cosine similarity of their embeddings, and correlate those scores against human judgements. The correlation — Spearman’s ρ — tells you whether the model’s sense of “similar” matches a clinician’s.
The problem is that the standard STS datasets don’t reflect clinical language. STS-B uses news and captions. BIOSSES uses PubMed abstracts. Neither captures the telegraphic, abbreviation-heavy prose of an electronic health record (EHR) discharge note. The two established clinical STS datasets — MedSTS and the n2c2 2019 ClinicalSTS challenge — are no longer publicly accessible, and the n2c2 data carries a data use agreement that prohibits redistribution, so GitHub copies of it are out of bounds.
The practical consequence is that if you’re evaluating embedding models for clinical NLP, you have no clean off-the-shelf benchmark. The closest you get is BIOSSES, which is a reasonable proxy but a different register. I needed to build a dataset of STS pairs for an evaluation of contrastive fine-tuning for EHR notes, and this tool was vibe-coded with Anthropic Claude to help with annotations.
What the tool does
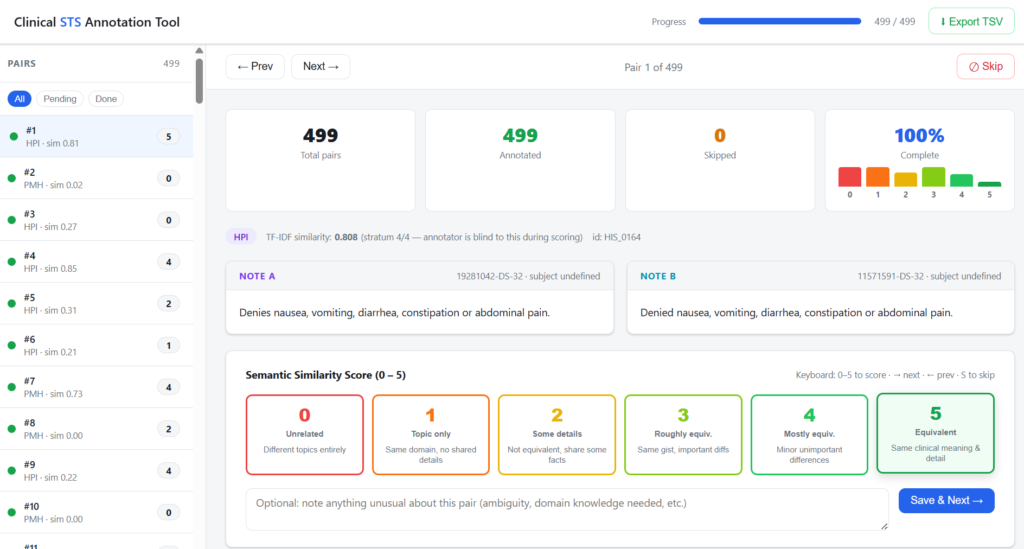
It takes a CSV of discharge note sections and produces a browser-based annotation interface for scoring sentence pairs 0–5 on the MedSTS scale. The pair generation uses stratified TF-IDF cosine sampling — the same methodology used to build MedSTS — which ensures annotations cover the full similarity range rather than clustering at zero (which happens when you sample pairs randomly from a clinical corpus, since most patient pairs are genuinely unrelated).
The stratification is the key design decision. Without it, annotators spend most of their time confirming that two unrelated patients are indeed unrelated, which produces a dataset that’s easy to evaluate on but uninformative. With it, roughly equal numbers of pairs appear at each similarity level, and the resulting benchmark actually discriminates between models.
One methodological detail worth noting: the TF-IDF similarity score computed during pair generation is displayed to the annotator only after they submit their score, not before. This avoids anchoring bias — the risk that seeing a numerical similarity estimate nudges the annotator toward a particular score rather than making an independent clinical judgement.
Preprocessing
The tool expects notes already split into labelled sections — columns for note_id, section, and text. This is because it was custom-built for MIMC-IV-EXT-BHC notes, which have labelled sections. It currently handles six section types, each with a different splitting strategy:
- History of Present Illness and Social History are split on sentence boundaries, with protection for clinical abbreviations (s/p, h/o, b.i.d., etc.) that would otherwise trigger false splits.
- Physical Examination is split on system examination headers (HEENT:, CV:, ABD:, NEURO:, etc.), which are more reliable delimiters than punctuation in templated PE text. Checkbox-format physical exams — common in some EHR systems — are filtered out entirely, since they can’t be annotated for semantic similarity in any meaningful way.
- Past Medical History, Discharge Diagnosis, and Chief Complaint are used as whole entries, since they are already short enough to annotate directly and splitting them would destroy their clinical meaning.
If your notes are not yet section-labelled, you will need to run a section segmentation step first. For MIMIC-IV data the sections are typically present as structured fields; for other corpora, a rule-based or model-based section splitter would be needed before the tool can be used.
The output
Annotations export as a tab-separated file with the same column structure as MedSTS: sentence pairs, scores, and metadata. This drops directly into a sentence-transformers STS evaluation pipeline with no further processing.
The tool is available on GitHub under the MIT licence. It requires Python 3.10+, Flask, scikit-learn, and numpy — no GPU needed. Pair generation takes about 30 seconds for 500 notes; annotation of 200 pairs takes roughly an hour for a single annotator working at a comfortable pace.
Leave a Reply