Category: Data
-
Teaching an Old Trick to a Newer, Smarter Dog
—
A context-sensitive neural spell checker for clinical text, built on BioClinical-ModernBERT Source code: github.com/eukairos/spellcheck • MIT License The problem with spell-checking clinical notes Clinical documentation is full of spelling errors. That is not a criticism of clinicians — it is a structural reality. Notes are written at speed, on shift, using a vocabulary that sits…
-
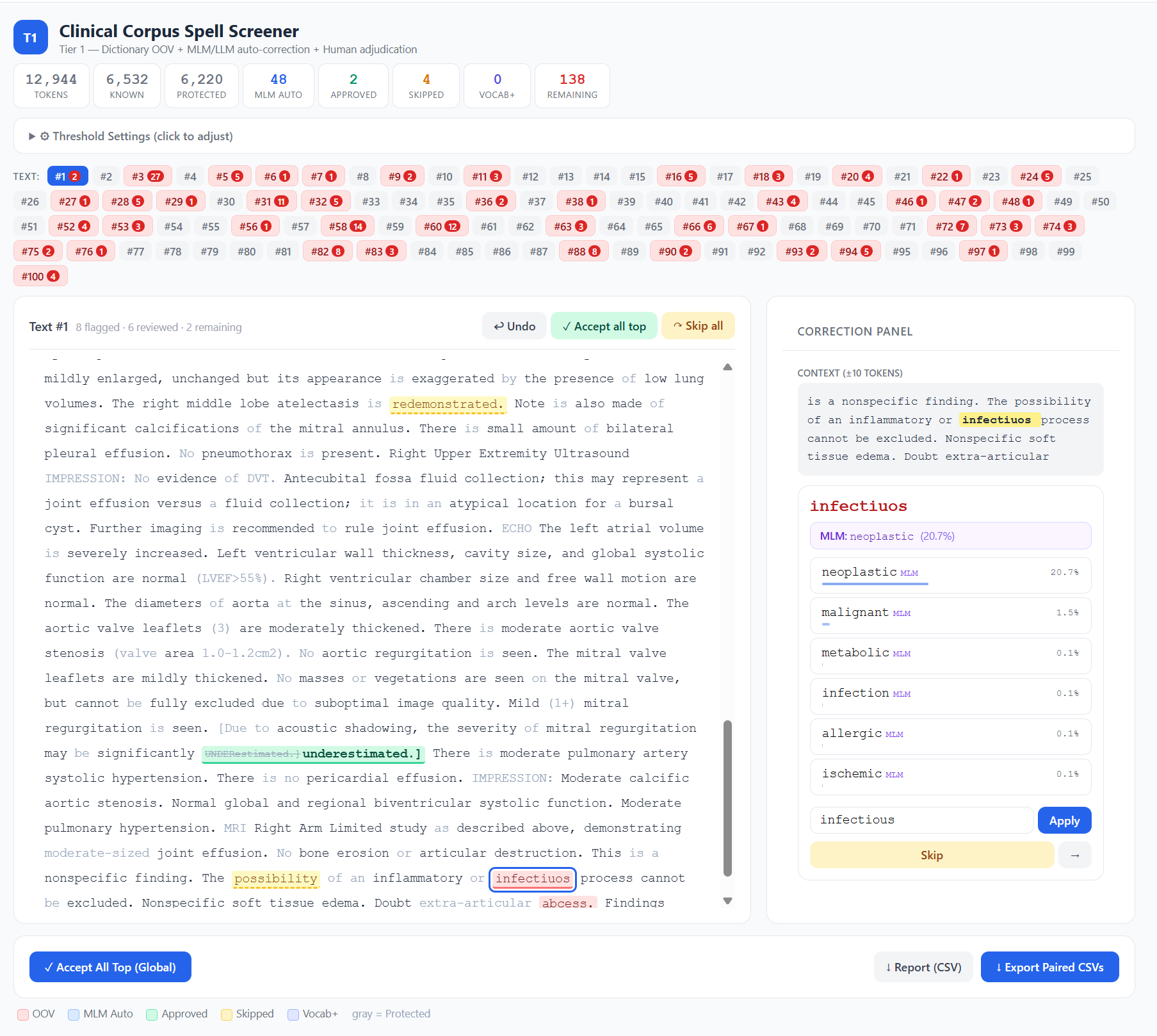
Building a Spell Screener for Clinical Text — And How You Can Adapt It for Any Domain
—
Clinical notes are peculiarly messy. Written under time pressure by busy clinicians, they’re full of abbreviations, shorthand, and — inevitably — typos. When you’re building natural language processing (NLP) pipelines that depend on these notes, these ‘features’ become a real problem. This post describes a tool Anthropic’s Claude helped me build to tackle that problem,…
-
The Vector Space Model for Text Processing
This is a short post describing the geography of the Vector Space Model (VSM) of natural language processing (NLP). I initially wrote it as a section within a topic modelling post, but found the research material too extensive to fit into a single blog, so it is carved out here as a primer for NLP.…
-
Topic Modelling 3b: BERTopic Part 2
In our last post, we looked at how BERTopic works. In the accompanying Jupyter notebook, we used BERTopic to extract topics from 5000 random PubMed abstracts from a dataset assembled by Huggingface user owaiskha9564. Here, we’ll run through the results, to illustrate what we can do with BERTopic. Discovered Topics After clustering and finetuning, the…
-
Topic Modeling 3a: BERTopic Part 1
BERTopic is a sophisticated topic modelling technique that combines traditional natural language processing (NLP) and language models (LM). It takes a bit of digging to understand the workings of BERTopic, but I think it is worthwhile because the library seems to be maintained and continues to be updated with integrations to modern LM libraries like…
-
Topic Modelling 2: Latent Dirichlet Allocation
—
Latent Dirichlet Allocation (LDA) is a probability-based topic modelling approach that treats documents as bags-of-words. Conceptually it is similar to Latent Semantic Analysis (LSA, discussed in the previous post) in that it tries to discover a latent space from observed variables, but instead of a deterministic matrix factorization, it uses probability distributions on random variables.…
-
Topic Modelling 1: Latent Semantic Analysis
—
in DataTopic Modelling is a machine learning task. It aims to identify main themes, or subjects, in a corpus of documents. Its uses in healthcare include classifying PubMed entries, extracting diagnoses from clinical notes and generating keywords from a collection of hospital policy documents. The underlying intuition behind topic modelling is that a corpus of documents…
-
Building a MIMIC-IV Patient Graph
—
A Simple Patient Graph Database. In a previous post, I shared how to build a SNOMED concept graph database. In this post, we will use the MIMIC-IV dataset (details below) to construct a graph of patients, their admissions and the diagnoses associated with each admission. We then link this graph to our SNOMED concept graph…
-
Building a SNOMED Concept Graph
—
SNOMED Is A Knowledge Graph The Systematized Nomenclature of Medicine, Clinical Terms (SNOMED CT) is a de facto standard for standardizing clinical vocabulary and ontology in many parts of the world, including in Singapore. You can access SNOMED CT in a number of ways. If you work in a large healthcare organization, it probably has…
-
Adjacent Possibles
—
Welcome to Eukairos, a collection of musings at the confluence of artificial intelligence (AI), data management and healthcare. The term eukairos is derived from the Greek ευκαιρός, loosely meaning ‘timeliness’ or ‘opportunity’. The short explanation for the site’s name is that English-language domain names are pretty much saturated in the .sg domain. The more involved…